联系电话:020-88888888
联系电话:020-88888888
反向传播学习连接:前向传播、反向传播——通俗易懂_马鹏森的博客-CSDN博客_前向传播 反向传播
1、反向传播 是 求解损失函数关于各个参数的梯度的一种方法。(求梯度【偏导数】)
2、梯度下降 是 根据反向传播计算得到的梯度(偏导)来更新各个权重W,使损失函数极小值的一种方法。(使权重W更好)
学习率? α 是梯度下降中权重更新公式的一部分
梯度下降中的权重更新公式:
利用,权重更新公式?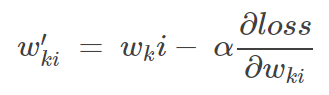 更新权重W,其中? α? 是学习率
更新权重W,其中? α? 是学习率
备注:我认为:学习率? == 步长
梯度下降属于优化器的一种,优化器就是使使损失函数极小值的一种方法,它里面也包含学习率
在机器学习、深度学习中使用的优化算法除了常见的梯度下降,还有 Adam,Adagrad,RMSProp 等几种优化器
理解了上面的内容后,我们便知道了整个神经网络的实现过程分为5步:(Pytorch实现神经网络_马鹏森的博客-CSDN博客)
前向传播得到预测值 --> 求预测值与真实值的损失 -->?优化器梯度清零(可选操作)?--> 利用反向传播求所有参数的梯度(导数)?--> 优化器更新权重W
备注:这里的optimizer.zero_grad()? 是梯度清零操作,需要的内存较大,如果使用“梯度累加”操作的话:在内存大小不够的情况下叠加多个batch的grad作为一个大batch进行迭代,因为这个和大batch_size得到的梯度是等价的,但是效果自然是差一些,这个可以说是“增大batch-size减少内存”的一个小trick吧
PyTorch中在反向传播前为什么要手动将梯度清零? - 知乎
损失函数与优化器理解+【PyTorch】在反向传播前为什么要手动将梯度清零?optimizer.zero_grad()_马鹏森的博客-CSDN博客

某某自来水业务系统,是一套适合各种规模自来水公司的网络版自来水多种类业务管理软件。根据各大自来水公司存在的问题和需求自主...

某某自来水业务系统,是一套适合各种规模自来水公司的网络版自来水多种类业务管理软件。根据各大自来水公司存在的问题和需求自主...

某某自来水业务系统,是一套适合各种规模自来水公司的网络版自来水多种类业务管理软件。根据各大自来水公司存在的问题和需求自主...

某某自来水业务系统,是一套适合各种规模自来水公司的网络版自来水多种类业务管理软件。根据各大自来水公司存在的问题和需求自主...
 QQ:88888888
QQ:88888888 13899999999
13899999999

 返回顶部
返回顶部
